How I Actually Use AI — Hub, Swarm, and Local-First
One operator, 100+ projects — Cursor as conductor, Ollama on the Ryzen box, MSI for long runs, and cloud models only for decisions that need eyes.
- cursor
- agents
- ollama
- local-first
- homelab

I’m a solo founder in Muskogee running a 501(c)(3), a web agency, trading experiments, and a pile of desktop apps — from one workspace with 100+ project folders. AI isn’t a chatbot I ask for poems. It’s infrastructure: routing, memory, and labor I can’t afford to hire.
AI-assisted, human-verified everywhere. I architect; agents implement; I merge what I understand.
The mental model: hub and spokes
One repo — ORGANIZATION — is the hub. Client sites, Tauri apps, trading bots, and docs live in spokes (01_web_design/, 05_apps_and_extensions/, etc.). The cloud agent in Cursor is the conductor, not the orchestra.
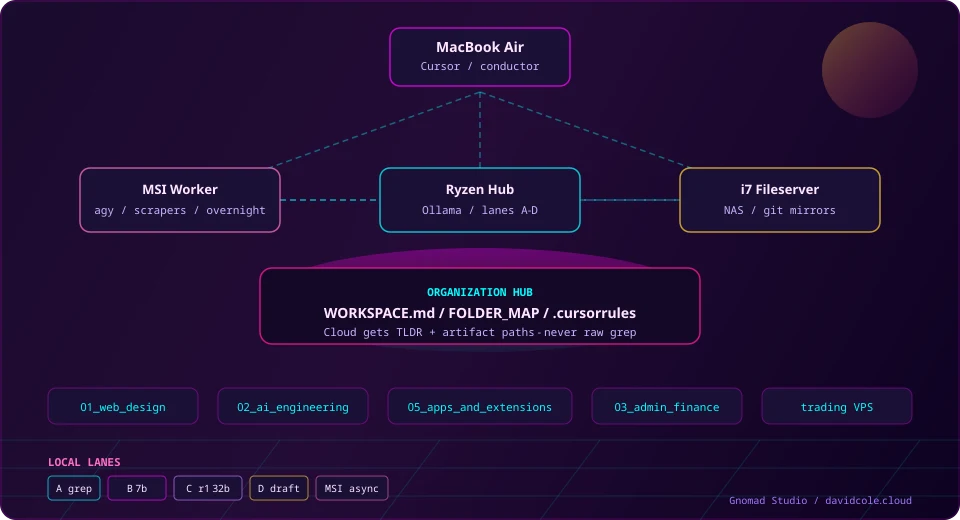
| Role | Machine | What it does |
|---|---|---|
| Conductor | MacBook Air | Cursor — routing, review, surgical edits |
| Local muscle | Ryzen desktop | Ollama, grep, doc crunch, lane A–D |
| Night shift | MSI laptop | Scrapers, long prose, agy over SSH |
| Vault | i7 fileserver | NAS, Nextcloud, git mirrors |
| Spokes | 100+ folders | One project per path — scoped agent sessions |
I never dump the whole tree into chat. I read a map (WORKSPACE.md, FOLDER_MAP.md), scope to one spoke, and hand the cloud agent a TLDR plus artifact paths — not raw logs.
Classify first, then pick a lane
Every non-trivial task starts with:
python3 scripts/context-stack/local-offload.py classify "<what I'm doing>"That routes into lanes:
| Lane | Engine | Typical work |
|---|---|---|
| A | No LLM | grep, stats, pandoc, ctx_execute sandbox |
| B | qwen 7b (4060) | Fast summaries, copy crunch |
| C | deepseek-r1 32b | JSON plans, reasoning |
| D | LLaDA diffusion | Long prose drafts |
| async | MSI agy | Blog batches, scrapers, 20+ min jobs |

Cloud Cursor reads CLOUD_TLDR.md or .agents/LOGS/offload-handoff.json — never re-runs the gather. That alone saves roughly 85–90% of tokens vs pasting git status and find into chat. Full pipeline: Documenting 100+ Projects.
Cursor: rules, skills, and Ponytail
Cursor is my primary IDE. The hub repo carries .cursorrules and domain rules so every session knows:
- Folder map discipline — check the index before grepping the universe
- Local housekeeping — cloud agent applies patches; local scripts do audits
- Context-mode — analyze in sandbox code, stdout only
- Ponytail lite — YAGNI on leaf apps; orchestration infra is explicitly allowed on the hub
I pull patterns from a 573-skill library (SKILL_LIBRARY/) into project .agents/SKILLS/ when a spoke needs them. Recurring work becomes a SKILL.md, not a re-explained prompt. Token stack deep-dive: Headroom and Ponytail.
Multi-model review when stakes are high
For security-sensitive or cross-platform desktop work (Gnomad Slate, Webcanvas), I don’t trust one model. I run parallel reviews through NVIDIA NIM — GLM, Kimi, Nemotron, Qwen — merge P0 consensus, then implement.

Reports land in reviews/; the cloud agent gets the synthesis, not four full dumps. Greenfield apps use the project agentic loop: brief → local planner → expert panel → phased build. Cloud reads LOOP_STATE.json and PANEL_SYNTHESIS.md only.
Personas: INKWELL and QUILL
Long-form posts for davidcole.cloud use two voices:
| Persona | Role |
|---|---|
| INKWELL | Technical blog MDX — scripts/context-stack/prompts/inkwell-blog.md |
| QUILL | Session chronicle — npm run chronicle |
Inkwell is supposed to run on local 14b/heavy lanes. Honest failure today: I tried generating this post with local 7b and 14b via the Inkwell prompt. Both ignored the assigned topic and wrote generic “AI content creation” essays. I wrote this note manually from real stack docs.
Lane D/heavy is not fire-and-forget yet — it needs tighter prompt enforcement or QUILL chronicle input before I trust auto-drafts.
generate-davidcole-notes.sh now rejects responses that do not mention the POST TOPIC slug before any MDX lands on the site.
Trading VPS: agents with memory
Paper trading on a Hostinger VPS (discipline over dopamine) now has Hermes — a nightly meta-agent that reviews fills, updates per-bot knowledge bases, patches bounded .env keys, and exports SFT JSONL for weekend training on the MSI.
Details: Hermes on the VPS. Repo: VPS_Agent.
Hardware honesty
- Dual GPU Ollama on Nobara (5060 Ti + 4060) — warm 7b for fast crunch, unload before loading 32b reasoner. I stop Ollama when I’m not using it; GPUs run hot.
- RTK + Headroom shrink shell output 60–90% before it hits the model.
- Tailscale ties the mesh together without exposing Ollama to the internet (
127.0.0.1only).
What I don’t do
- Send secrets or VAULT paths to RAG or cloud context
- Let agents run repo-wide
findwithout a map lookup first - Trust agent output without
npm run build/cargo teston the spoke - Auto-publish Inkwell drafts without reading them
The pattern in one line
Directive → classify → local gather → cloud applies → human checkpoint → chronicle.
That’s how one person ships client sites, desktop alphas, and a trading stack without pretending to be a team of twelve.
What I’d do differently
I should have built the handoff contract (TLDR + JSON artifacts) before scaling to 100 projects — not after the third “why is Cursor slow” meltdown. Earlier Hermes-style memory on the trading VPS would have saved weeks of re-reading JSONL by hand.
Next step: wire QUILL chronicle into the Inkwell brief automatically so lane D drafts start from session memory, not a static file.
Start here if you’re new: Agentic Workflows for Solo Developers · Headroom and Ponytail